新火种
2023-12-25
新火种
2023-12-25 


“Transformer挑战者”Mamba,用Macbook也能跑了!GitHub半天斩获500+星
“Transformer的挑战者”Mamba,用MacBook也能跑了!
有大佬在GitHub上共享了一份笔记,让人们可以用最简单的方式运行Mamba。
这份共享中,算上说明书一共只有三个文件,而且发布不到一天,就斩获了500+星标。
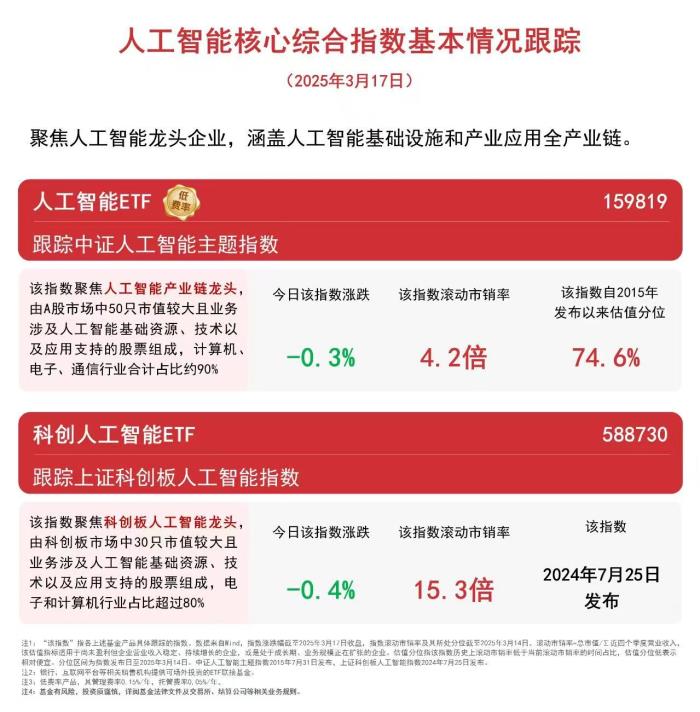
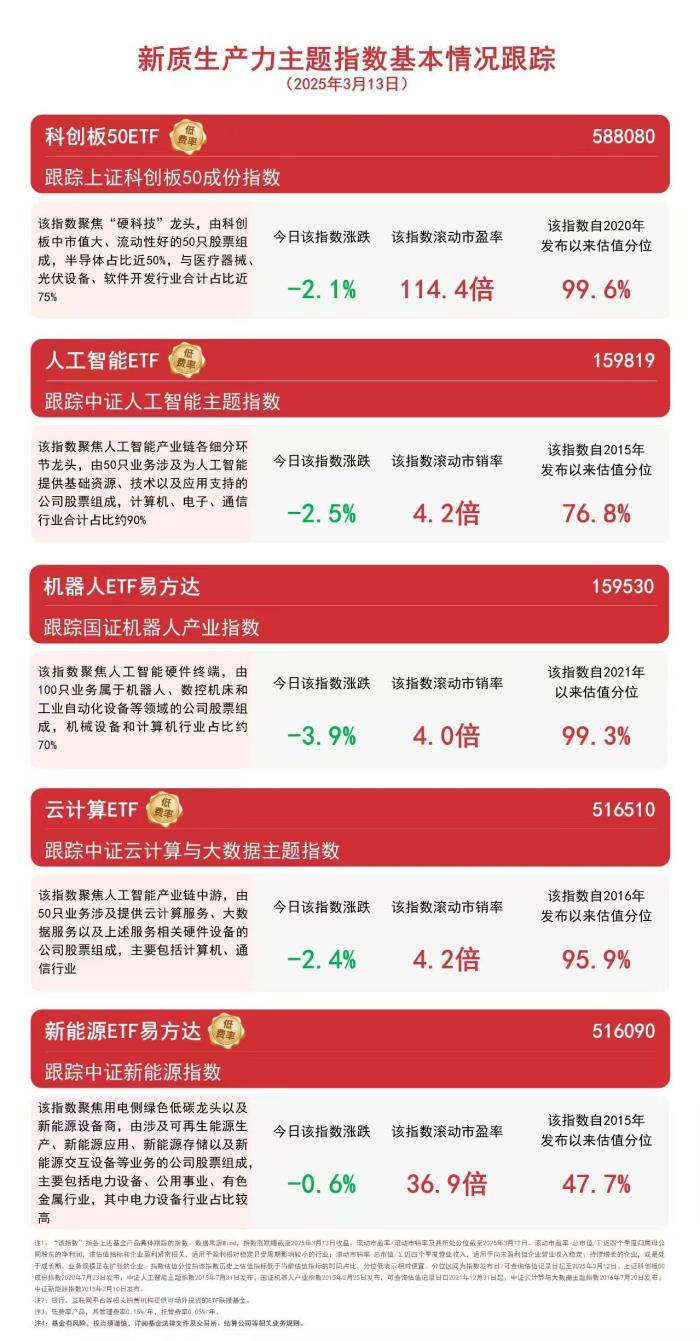
Mamba是一种新的大模型架构,在语言任务上的表现可以与两倍规模的Transformer一决雌雄。
但官方给出的只有模型文件,需要一定专业知识才能部署使用,而且要Linux+N卡才能运行。

有了这份笔记,Mamba的运行步骤大大简化,而且也不再要求N卡,M系列的MacBook也能跑了。
从事相关专业的网友看了表示,这种简单化的模型实在是太棒了,希望自己的工作也能朝着这个方向进展。

原版Mamba的作者Tri Dao和Albert Gu也转发了这份笔记,并对它的简洁性和易读性给予了肯定。
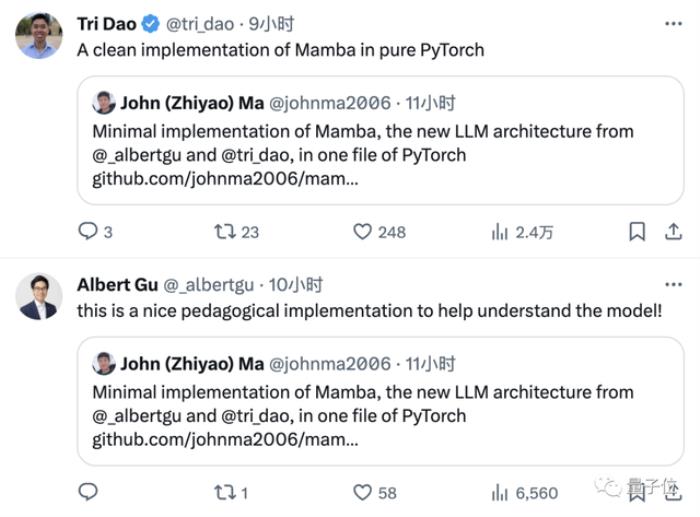
那么,这份笔记该如何使用呢?
两个文件即可运行首先,打开一个能运行PyTorch笔记的工具,比如Jupyter、VSCode,或者在线的谷歌Colab等。
然后下载作者的笔记和Python脚本,用Colab的话也可以使用GitHub导入功能。
如果在本地运行,需要把两个文件放到同一个目录;如果用Colab,则需要在连接成功后把model.py上传。
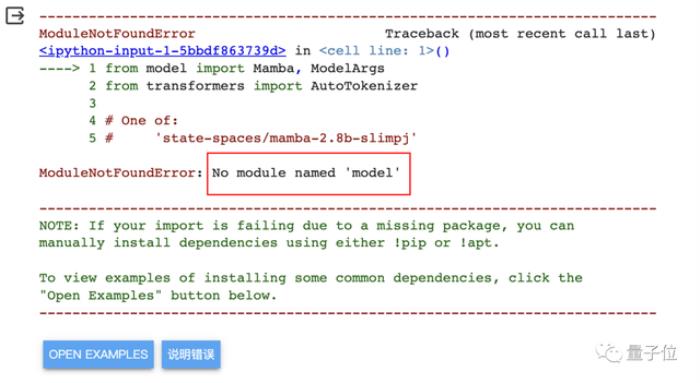
△如果不上传,会出现“找不到‘model’”的报错
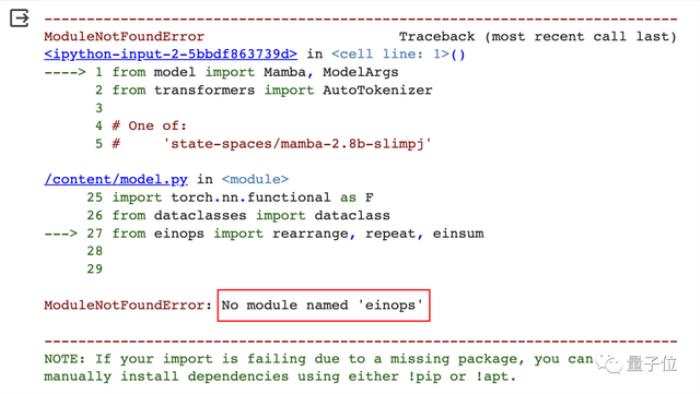
之后是安装所需的依赖环境,Colab需要手动安装的是einops,其他工具可以根据报错信息判断缺少的依赖。
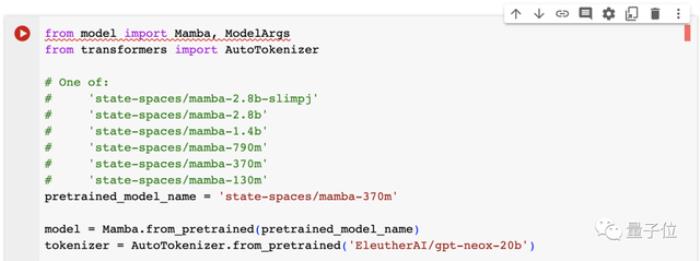
解决好依赖问题后,就可以点击笔记第一组中的运行按钮了,这里可以对模型规模进行选择,默认370M。
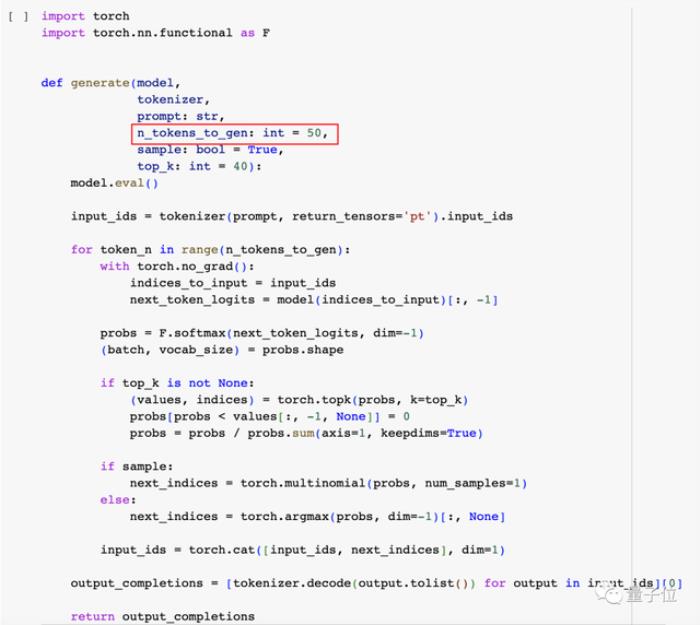
接下来是初始化,直接点击运行按钮即可。
这里也可以对输出token的数量进行调节,默认是50。
接着,笔记中给出了一些实例,我们也可以修改单引号之间的prompt内容(换行用n表示),然后点击运行。
不过需要注意的是,这里的prompt和我们平时用ChatGPT等bot型应用的方式有所区别。

这里可以借用一下Hugging Face中Llama 2的系统提示词:

性能上,在默认的规模和输出长度(370M,50token)下,输入Once Upon a time,在纯CPU版Colab中需用时约1分钟,在TPU上的用时则约为30秒,内存消耗在3到4GB之间。

在M1芯片的Mac上,以相同设置处理同样的内容,则需花费1分半左右。

不过作者也解释道,出于易读性的考虑,去掉了原版Mamba中的一些加速指令。

相关推荐

- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
热门文章