

 新火种
2023-12-25
新火种
2023-12-25 


语音识别技术
语音识别技术
1. 基础知识
1.1 语音识别概念
语音识别是将人类的声音信号转化为文字或者指令的过程([1])。语音识别以语音为研究对象,它是语音信号处理的一个重要研究方向,是模式识别的一个分支,其研究涉及微机技术、人工智能、数字信号处理、模式识别、声学、语言学和认知科学等许多学科领域,是一个多学科综合性研究领域([2])。
1.2语音识别分类
语音识别系统根据对说话人说话方式的要求,可以分为孤立字(词)语音识别系统、连接字语音识别系统和连续语音识别系统;根据对说话人的依赖程度可以分为特定人和非特定人语音识别系统;根据词汇量大小可以分为小词汇量、中等词汇量、大词汇量以及无限词汇量语音识别系统([3])。2. 发展趋势
20世纪50年代:语音识别的研究从上个世纪50年代开始,1952年,三位贝尔实验室的研究人员研究出了世界上第一个能识别10个英文数字发音的系统——Audry系统。该系统被普遍认为是自动语音识别系统的开端。20世纪60年代:60年代计算机的应用推动了语音识别的发展。其中动态规划(DP)和线性预测分析技术(LP)等技术的提出和运用对语音识别的发展产生了深远影响。20世纪70年代:70年代LP技术得到进一步发展,动态时间归正技术(DTW)基本成熟。特别是矢量量化(VQ)和隐马尔可夫模型(HMM)理论在实践上的运用初步实现了基于线性预测倒谱和DTW技术的特定人孤立语音识别系统。20世纪80年代:20世纪80年代随着HMM模型和人工神经元网络(ANN)等技术在语音识别中的成功应用人们终于在实验室突破了大词汇量、连续语音和非特定人这三大语音识别障碍。首次把这三个特性都集成在一个系统中,比较有代表性的是卡耐基梅隆大学研发的Sphinx系统。20世纪90年代:90年代之后语音识别与自然语言处理相结合发展到基于自然口语识别和理解的人机对话系统。与机器翻译技术相结合逐步发展出面向不同语种人类之间交流的直接语音翻译技术。语言识别技术在中国的发展
我国的语音识别研究工作一直紧跟国际水平国家也很重视并把大词汇量语音识别的研究列入“863”计划由中科院声学所、自动化所及北京大学等单位组织研究开发。目前国内也涌现出了诸如科大讯飞和北京捷通等专业研究和开发语音识别产品的高科技公司([3])。3. 主流工具
语言转写:

字幕生成:

3.1 具体案例应用
工具1:AppTek
描述:
为人类语言技术提供了前沿的机器学习、生成式人工智能支持,覆盖超过80种语言和方言。主要功能:
自动语音识别 (Automatic speech recognition ASR) 文段切分字幕生成1) Automatic captioning 实时生成字幕2) Post-editing transcription 后期编辑3) Digital Assent Management 数字资产管理4) Accessibility Solutions for Deaf/Hard of Hearing 对听力障碍者友好3. 自然语言理解 (Natural Language Understanding NLU)具体实例:
We should meet tomorrow at the booth at 2 pm.
Step 1: Named Entity RecognitionWe (person) should meet tomorrow (date) at the booth (location) at 2 pm (time).
Step 2: Intent ClassificationWe (person) should (modifier) meet (action) tomorrow (date) at the booth (location) at 2 pm (time).
Step 3: Inverse Text NormalizationWe (person) should (modifier) meet (action) tomorrow (date) at the booth (location) at 2 pm (time—13:00:00 UTC).
Step 4: ReasoningStep 5: DialogWe should meet tomorrow at the booth at 2 pm.
How about Tuesday?
Step 6: Knowledge GraphHow about Tuesday? (Tuesday=Nov.21)
Step 7: Sentiment Analysis
We should meet tomorrow at the booth at 2 pm.
How about Tuesday?
You know that’s not possible! (sentiment: negative)
工具2:IFlytek(科大讯飞)
操作步骤:
1. 导入音频/智能硬件:来自手机文件的音频连接录音笔使用(有免费的转写权益)
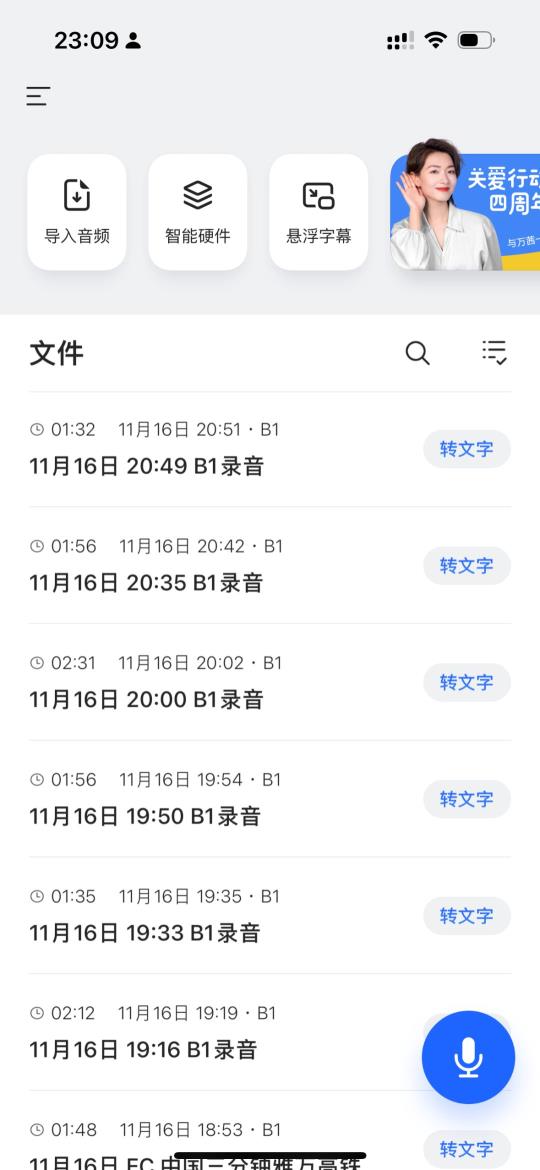
2. 悬浮字幕3. 转文字(付费/录音笔免费):支持多语种、多个说话人、转写后编辑
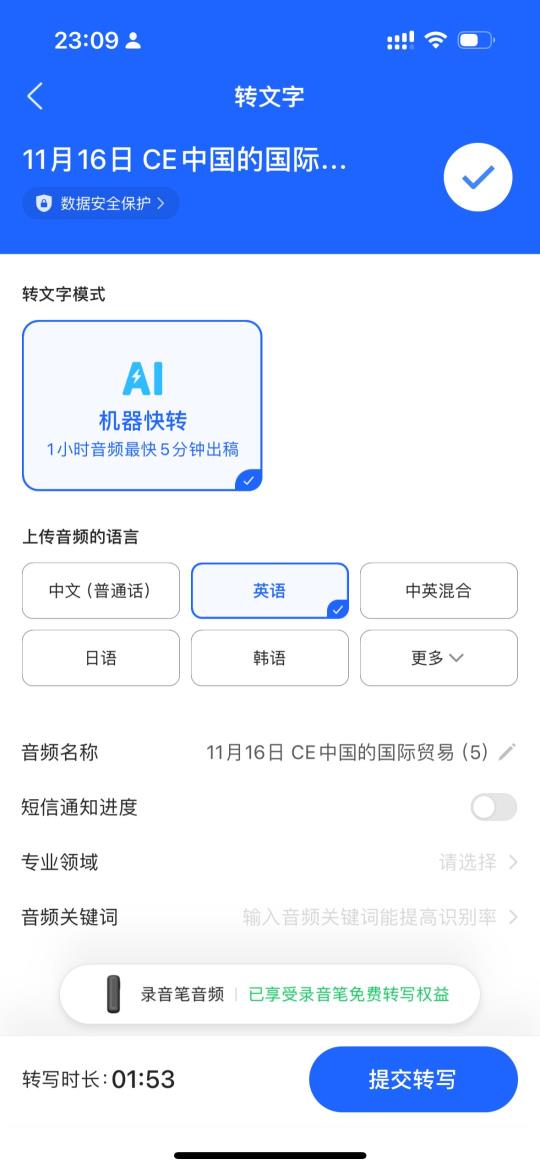

注:科大讯飞转写准确度也有待加强,在上下文语境充分的情况下,也会出现“识别错误”“语法错误”等基础错误。如图中的:COVID-19被识别成了Covey 19;If compared to the developed countries around the world被转写成了It compared to the developed countries
在软件转写准确性有待提高的情况下,人工后续的编辑成本就会上升。
4. 总结与启发
语音识别技术未来市场潜力巨大。目前已广泛应用在日常生活中的语音操作、人机交流等领域。对于翻译从业者来说,语音识别技术的发展可以实现口语识别技术、翻译技术和语音合成技术等([4]),帮助译者降低部分认知和输出负荷,进而提升翻译的效益和整体质量。参考文献:[1] 中华人民共和国国家质量监督检验检疫总局.GB/T21023 ⁃ 2007 中文语音识别系统通用技术规范[S].北京:中国标准出 版社,2007.[2] 王文慧.基于ARM的嵌入式语音识别系统研究[D].天津:天津 大学,2008.[3] 马志欣,王宏,李鑫.语音识别技术综述[J].昌吉。学院学报,2006(3):93⁃97.[4] 禹琳琳.语音识别技术及应用综述.现代电子技术 36.13(2013):43-45.特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
- END -
原创来源:北外CAT课程展示-张莹玥
推文
相关推荐


- 免责声明
- 本文所包含的观点仅代表作者个人看法,不代表新火种的观点。在新火种上获取的所有信息均不应被视为投资建议。新火种对本文可能提及或链接的任何项目不表示认可。 交易和投资涉及高风险,读者在采取与本文内容相关的任何行动之前,请务必进行充分的尽职调查。最终的决策应该基于您自己的独立判断。新火种不对因依赖本文观点而产生的任何金钱损失负任何责任。
