Softmax注意力与线性注意力的优雅融合,AgentAttention推动注意力新升级
来自清华大学的研究者提出了一种新的注意力范式——代理注意力 (Agent Attention)。近年来,视觉 Transformer 模型得到了极大的发展,相关工作在分类、分割、检测等视觉任务上都取得了很好的效果。然而,将 Transformer 模型应用于视觉领域并不是一件简单的事情。
来自清华大学的研究者提出了一种新的注意力范式——代理注意力 (Agent Attention)。近年来,视觉 Transformer 模型得到了极大的发展,相关工作在分类、分割、检测等视觉任务上都取得了很好的效果。然而,将 Transformer 模型应用于视觉领域并不是一件简单的事情。
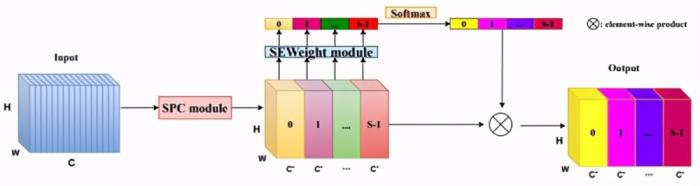
转载:Bestsong简介(1)Pyramid Split Attention Block用于增强特征提取(2)即插即用,可将Pyramid Split Attention Block取代ResNet的3×3卷积,提出基准网络ESPANet(3)目标分类与目标检测任务达到state-of-the-a

CPU+GPU,模型KV缓存压力被缓解了。来自CMU、华盛顿大学、Meta AI的研究人员提出MagicPIG,通过在CPU上使用LSH(局部敏感哈希)采样技术,有效克服了GPU内存容量限制的问题。与仅使用GPU的注意力机制相比,MagicPIG在各种情况下提高了1.76~4.99倍的解码吞吐量,并

谷歌大改Transformer,“无限”长度上下文来了。现在,1B大模型上下文长度可扩展到1M(100万token,大约相当于10部小说),并能完成Passkey检索任务。

只有一层或两层、且只有注意力块的transformer,在性能上有望达到96层、兼具注意力块与MLP块的GPT-3的效果吗?作者 | Mordechai Rorvig编译 | bluemin编辑 | 陈彩娴在过去的两年里,基于Transformer架构开发的大规模语言模型在性能(如语言流畅度)上达到

财联社1月6日讯(编辑 周子意)OpenAI首席执行官Sam Altman在1月6日的最新个人博客中写道,OpenAI将有信心构建通用人工智能(AGI),并且公司已经开始将目标转向“超级智能(superintelligence)”。奥尔特曼还指出,“我们热爱现在的产品,但我们在这里是为了辉煌的未来。

改进Transformer核心机制注意力,让小模型能打两倍大的模型!ICML 2024高分论文,彩云科技团队构建DCFormer框架,替换Transformer核心组件多头注意力模块(MHA),提出可动态组合的多头注意力(DCMHA)。DCMHA解除了MHA注意力头的查找选择回路和变换回路的固定绑定

机器之心报道编辑:陈PyTorch实现各种注意力机制。注意力(Attention)机制最早在计算机视觉中应用,后来又在 NLP 领域发扬光大,该机制将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。2014 年,Google DeepMind 发表《Recurrent Models

Kimi背后的长上下文处理机制曝光了!这项名为MoBA的新型注意力机制,能将处理1M长文本的速度一下子提升6.5倍,而且还是经过Kimi平台实际验证的那种。

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。注意力机制会计算一定跨度内输入文本(令牌,Token)之间的交互,从而实现对上下文的理解。随着应用的发展,高效处理更长输入的需求也随之增长 [1][2],这带来了计算代价的挑