首个AI高考全卷评测结果发布:最高分303数学全不及格
19日讯,上海人工智能实验室旗下司南评测体系OpenCompass选取了7个大模型进行高考“语数外”全卷能力测试。OpenCompass发布了首个大模型高考全卷评测结果。语数外三科加起来的满分为420分,此次高考测试结果显示,阿里通义千问2-72B排名第一,为303分,OpenAI的GPT-4o排名
19日讯,上海人工智能实验室旗下司南评测体系OpenCompass选取了7个大模型进行高考“语数外”全卷能力测试。OpenCompass发布了首个大模型高考全卷评测结果。语数外三科加起来的满分为420分,此次高考测试结果显示,阿里通义千问2-72B排名第一,为303分,OpenAI的GPT-4o排名

科技日报讯(记者张佳欣)量子计算机在解决拓扑学难题上展现出巨大潜力。据英国《自然》网站日前报道,总部位于英国剑桥的Quantinuum公司研究人员在arXiv网站发布预印本论文称,他们可利用量子计

被誉为“工业软件之芯”的求解器,长年由国外垄断,国产自研进度如何了?最近,工信部产业发展促进中心等单位专门举办了一场比赛(首届能源电子产业创新大赛),让国产求解器在电网调度的复杂场景下PK了一番。为什么求解器这么受重视?
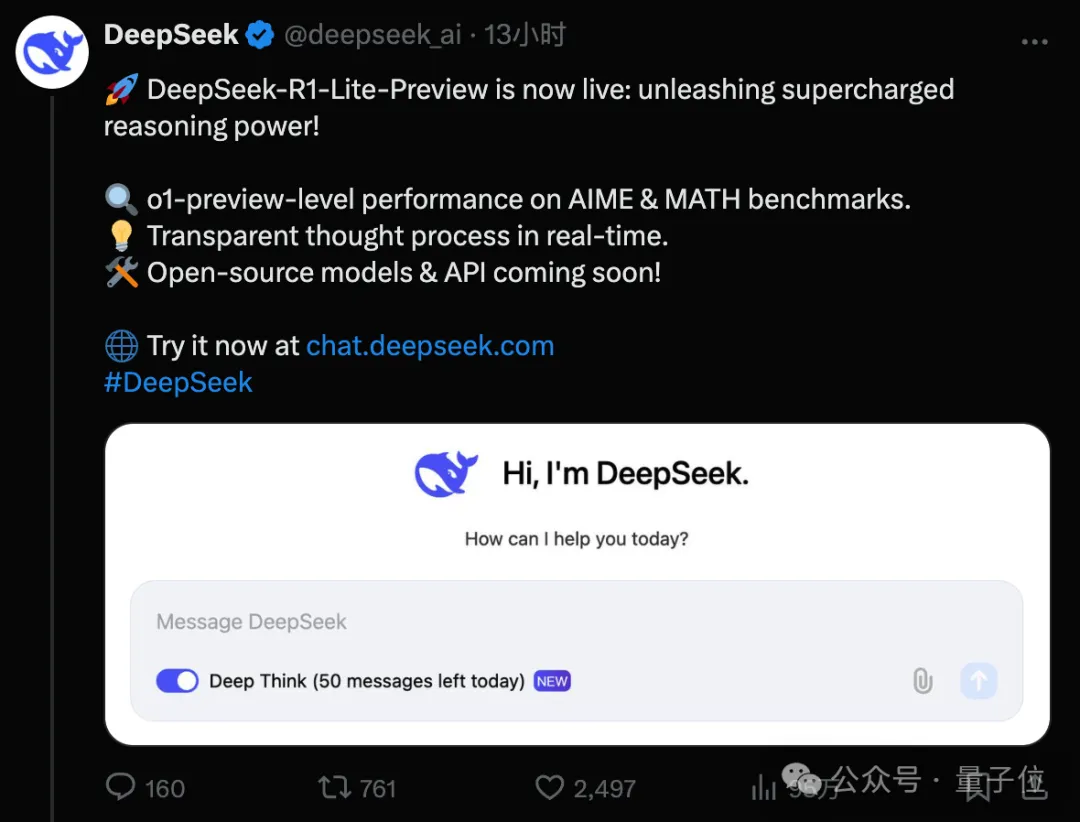
DeepSeek版o1来了,发布即上线,现在就能玩!模型名为DeepSeek-R1-Lite,预览版在难度较高数学和代码任务上超越o1-preview,大幅领先GPT-4o等。据了解,DeepSeek-R1-Lite使用强化学习训练,推理含大量反思和验证,遵循新的Scaling Laws——推理越长

中山大学和华为等机构的研究者提出了 LEGO-Prover,实现了数学定理的生成、整理、储存、检索和复用的全流程闭环。背景作为长链条严格推理的典范,数学推理被认为是衡量语言模型推理能力的重要基准,GSM8K 和 MATH 等数学文字问题(math word problem)数据集被广泛应用于语言模型

阿里发布了Qwen2-Math(1.5B/7B/72B)系列,Qwen2-Math是一系列基于Qwen2 LLM构建的专门用于数学解题的语言模型,数学推理能力全球第一。在Math上的评测结果表明,最大
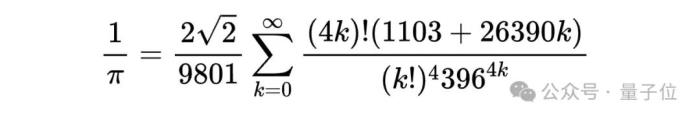
如果有这么一个人,写下这样的复杂公式,并声称是受女神梦中启发所得,大家伙儿通常会送他两个字:民科。但当这个人一生中数千次写下类似的数学公式和命题,并在此后的100年间,不断地被证实正确,那么就只有一个可能——他是拉马努金。

尤其是 GPT-4 求解数学问题的能力,可以说是雪崩式下降 —— 三月版 97.6% 的准确度到六月只剩 2.4%。

大模型对齐新方法,让数学推理能力直接提升9%。上海交通大学生成式人工智能实验室(GAIR Lab)新成果ReAlign,现已开源。

家人们,o1大模型,最近着实是有点火啊。就在今天,昆仑万维的Skywork o1首发中文逻辑推理能力,并开启了邀测。那一波实测,这不就得安排一下么。类似o1模型最大的特点就是其强悍的推理能力,因此,我们直接上一道AIME数学竞赛题,看看够不够“开门”。