SIGIR2023|30万真实查询、200万互联网段落,中文段落排序基准数据集发布
段落排序是信息检索领域中十分重要且具有挑战性的话题,受到了学术界和工业界的广泛关注。段落排序模型的有效性能够提高搜索引擎用户的满意度并且对问答系统、阅读理解等信息检索相关应用有所助益。在这一背景下,例如 MS-MARCO,DuReader_retrieval 等一些基准数据集被构建用于支持段落排序的
段落排序是信息检索领域中十分重要且具有挑战性的话题,受到了学术界和工业界的广泛关注。段落排序模型的有效性能够提高搜索引擎用户的满意度并且对问答系统、阅读理解等信息检索相关应用有所助益。在这一背景下,例如 MS-MARCO,DuReader_retrieval 等一些基准数据集被构建用于支持段落排序的

伴随着全球人工智能技术飞速进步,具身智能产业迅猛发展,赋予机器人类人化的泛化能力是具身智能机器人技术的核心目标之一,实现这一目标的关键在于如何使各类机器人本体在面对多样化的环境和任务时,能够展现出卓越的性能。正如ChatGPT需要海量文本数据来训练一样,想要培养出一个能力全面的机器人,也需要大量优质
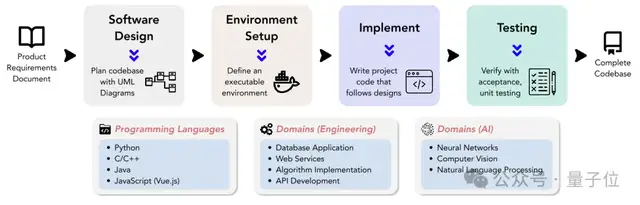
首个AI软件工程师Devin正式亮相,立即引爆了整个技术界。Devin不仅能够轻松解决编码任务,更可以自主完成软件开发的整个周期——从项目规划到部署,涵盖但不限于构建网站、自主寻找并修复 BUG、训练以及微调AI模型等。

随着大语言模型在众多领域的广泛应用,基准测试成为了评估模型质量的关键工具。但是,如果测试结果受到不当影响,例如操纵模型输出的长度或风格来操纵胜率,模型性能的排名可能因此失去可信度,进而直接影响整个行业的信任和技术进步。

要点:Meta发布了名为FACET的数据集,用于探测计算机视觉模型对某些“类别”人群的偏见。FACET包含32000张图片,50000人的图像,标注了职业和活动“类别”,以及人口统计和身体特征。FACET可用于测试模型在不同人口属性上的分类、检测、分割和定位任务的公平性。新火种(xinhuozhon

小K播早报|宁德时代否认小米事故车辆搭载其电池 OpenAI推出AI Agent评测基准

从蒸汽机、电气再到互联网,每一次革命都代表着科技的飞速发展和人类文明的巨大进步,现如今,随着生成式AI的广泛应用,以人工智能为代表的新一轮科技浪潮则正在引领整个社会走向第四次工业革命,作为一种模拟人类智能的技术,AI可以通过学习、推理和自我修正等方式实现自主决策和行动,

但当前的大部分评测基准仍然具有以下几个缺陷:多注重于短视频,视频长度或视频镜头数不足,难以考察到模型的长时序理解能力;对模型的考察局限在部分较为简单的任务,更多细粒度的能力未被大部分基准所涉及到;现有的基准仍可以仅凭单帧图像以获取较高的分数
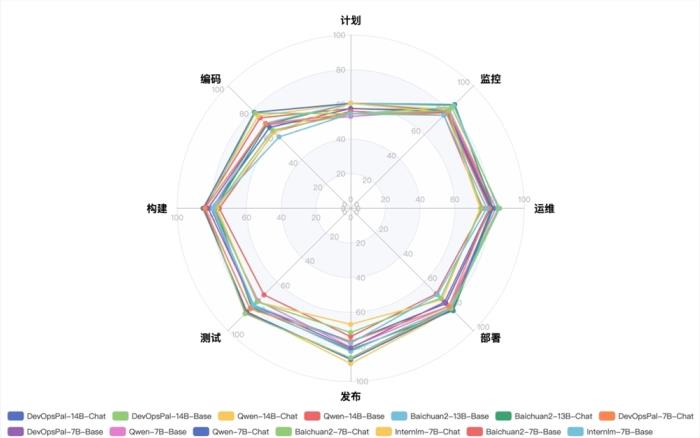
站长之家 11月2日 消息:蚂蚁集团联合北京大学发布了面向 DevOps 领域的大语言模型评测基准 ——DevOps-Eval。该评测基准包含了计划、编码、构建、测试、发布、部署、运维和监控等8个类别的选择题,共计4850道题目。此外,还针对 AIOps 任务做了细分,并添加了日志解析、时序异常检测

当前,人工智能大模型已迈入赋能千行百业的关键期。作为新质生产力的技术代表之一,人工智能大模型必将在产业升级的过程中起到决定性作用,培育未来产业,催生新模式、新业态,推动科技创新和产业创新融合发展。值此之际,由成都市经济和信息化局新经济发展委员会、成都高新区数字经济局指导,成都传媒产业集团主办,红星传