北大校友“炼丹”分享:OpenAI如何训练千亿级模型?
编译 |琰琰大规模深度神经网络训练仍是一项艰巨的挑战,因为动辄百亿、千亿参数量的语言模型,需要更多的 GPU 内存和时间周期。这篇文章从如何多GPU训练大模型的角度,回顾了现有的并行训练范式,以及主流的模型架构和内存优化设计方法。本文作者Lilian Weng现为OpenAI应用人工智能研究负责人,
编译 |琰琰大规模深度神经网络训练仍是一项艰巨的挑战,因为动辄百亿、千亿参数量的语言模型,需要更多的 GPU 内存和时间周期。这篇文章从如何多GPU训练大模型的角度,回顾了现有的并行训练范式,以及主流的模型架构和内存优化设计方法。本文作者Lilian Weng现为OpenAI应用人工智能研究负责人,

12日,北京大学联合字节跳动成立豆包大模型系统软件联合实验室,校企携手面向人工智能系统软件开展科学研究和技术转化,培养高素质创新型软件人才。

要点:北大和中山大学研究者提出的Chat-UniVi是一种统一的视觉语言大模型,能够在统一的视觉表征下同时处理图片和视频任务,且仅需三天训练即可获得130亿参数的通用视觉语言大模型。Chat-UniVi采用动态视觉token来统一表示图片和视频,通过最近邻的密度峰聚类算法获取动态视觉token,多尺
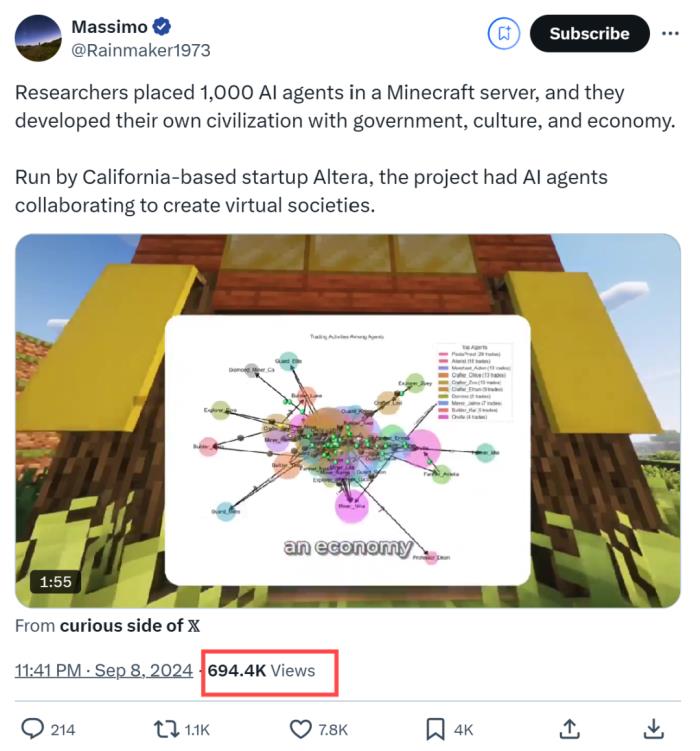
北大校友打造的1000个智能体「我的世界」,火爆AI圈!随便一条推文,都能引来几十万网友围观:在这里,有着真正意义上的虚拟社会,包括文化、经济、宗教……每个智能体在GPT-4加持下,都是社会中独立自主的个体。比如这位名叫Olivia的农民,受探险故事启发,曾中途决定撂下锄头去闯荡江湖…它们以宝石(g

最近,北大硕士通过DeepSpeed-Chat框架训练了一个RLHF对话模型。他在知乎分享了自己的实践过程,总结了原理,代码以及踩坑与解决方案。在训练奖励模型时,作者使用Cohere提供的问答数据,构造了2万个优质答案和劣质答案的组合

要点:1. LLaMA-Rider是一个训练框架,赋予大型语言模型在开放世界中自主探索、学习任务的能力,提高其适应开放环境的通用智能。2. LLaMA-Rider采用反馈-修改机制进行主动探索,在探索阶段将成功经验整合为监督数据集,然后用于微调模型,提高多任务解决的能力。3. LLaMA-Rider

4月7日,九州通宣布与北京大学武汉人工智能研究院(简称“北大武汉院”)联合成立“北大武汉院-九州通人工智能联合实验室”( 简称“实验室”),
要点:1. 北大数学课引入AI助教,提供学生和老师更好的学习和教学体验。2. AI助教名为Brainiac Buddy,基于GPT-4开发,帮助学生理解课程内容和解答问题。3. 董彬是该AI助教的创始人,旨在提高教学效率和个性化学习经验。站长之家10月25日 消息:北大数学课引入AI助教,为学生和老
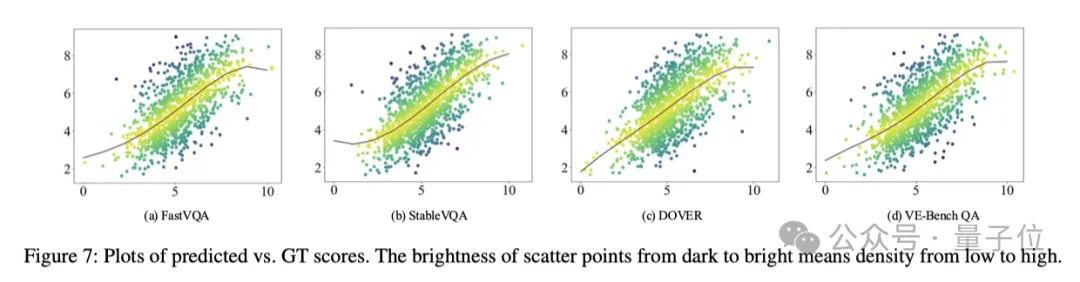
北京大学MMCAL团队 投稿新火种 | 公众号 QbitAI视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。它重点关注了AI视频编辑中最常见的一个场景:视频编辑前后结果与

EMNLP顶会落下帷幕,各种奖项悉数颁出。最佳长论文奖被北大微信AI团队收入囊中,由北大孙栩老师和微信周杰、孟凡东合作指导。他们发现了大模型中关键能力——上下文学习背后的工作机制。通过理解这一机制,还提出一系列方法来提高其性能。